
CGRA: Mảng phần cứng có khả năng tái cấu hình cấu trúc thô
Xu hướng phát triển khoa học công nghệ những năm qua chỉ ra rằng các thiết bị di động cầm tay chẳng hạn như các máy chơi nhạc MP4, máy tính bảng, các thiết bị trợ giúp cá nhân PDA, hay các máy điện thoại smartphone,… ngày càng trở nên thông minh hơn, mật độ tích hợp các ứng dụng chức năng ngày càng cao hơn. Các thiết bị này nói chung đều yêu cầu khả năng xử lý các chức năng tính toán chuyên sâu như truyền thông, chụp ảnh, quay phim, xem truyền hình, dịch vụ định vị toàn cầu… theo thời gian thực. Thực hiện phần cứng cho các thiết bị như vậy luôn là một thách thức đối với nhà thiết kế bởi các yêu cầu khắt khe như giảm kích thước và công suất tiêu thụ của vi mạch, tăng hiệu năng xử lý của ứng dụng, rút ngắn thời gian thiết kế và triển khai sản phẩm, đơn giản hoá quá trình nâng cấp thiết bị sau bán hàng,… Thêm vào đó khả năng hỗ trợ đa chuẩn (truyền thông hoặc mã hoá) của thiết bị cũng là yêu cầu ngày càng phổ biến bởi nó cho phép giảm giá thành tích hợp sản phẩm cũng như cho phép khách hàng có thể nhận được nhiều loại hình dịch vụ từ các nhà cung cấp dịch vụ khác nhau trên cùng một thiết bị.

Hình 1: So sánh giữa các phương pháp thực hiện hệ thống nhúng.
Về cơ bản, có hai phương pháp chủ yếu được sử dụng cho việc thực thi một chức năng mong muốn trong các hệ thống nhúng truyền thống (Hình 1). Một phương pháp là sử dụng mô hình tính toán được vận hành bởi luồng dữ liệu (dataflow-driven), chẳng hạn các vi mạch tích hợp chuyên dụng ASIC (Application Specific Integrated Circuit). Phương pháp thứ hai là sử dụng các bộ vi xử lý được vận hành bởi các lệnh (Instruction-driven) nạp sẵn trong bộ nhớ, chẳng hạn như các bộ vi lý nhúng của ARM, các bộ xử tín hiệu số DSP (Digital Signal Processor) hoặc các bộ xử lý có tập lệnh xác định cho một miền ứng dụng cụ thể ASIP (Application-Specific Instruction Set Processor). Tuy nhiên, cả hai phương pháp trên đều không thể thỏa mãn được tất cả các yêu cầu trong việc thực thi các ứng dụng đa phương tiện thế hệ tiếp theo [1]. Một vi mạch ASIC được thiết kế chuyên dụng cho một chức năng định trước vì thế nó được tối ưu để thực thi một cách hiệu quả nhất chức năng đó. Tuy nhiên, sau khi thiết kế đã được chế tạo thành vi mạch, chức năng của nó là không thể thay đổi. Nếu có bất kỳ yêu cầu nào về thay đổi chức năng, vi mạch cần phải được thiết kế và chế tạo lại. Quá trình này là khá tốn kém, đặc biệt nếu xem xét tới việc phải thay thế vi mạch đó trong một lượng lớn các hệ thống hoặc sản phẩm đã được triển khai ứng dụng. Ở thái cực kia, các bộ vi xử lý có độ mềm dẻo cao hơn bởi khả năng thực thi một chuỗi lệnh để hoàn thành một chức năng mong muốn. Bằng việc thay đổi chuỗi các lệnh chạy trên vi xử lý, chức năng của hệ thống sẽ được thay đổi mà không cần bất cứ sự hiệu chỉnh nào trong phần cứng. Tuy nhiên nhược điểm của các bộ vi xử lý là hiệu năng tính toán và hiệu quả sử dụng năng lượng thường thấp hơn nhiều so với mạch ASIC. Nguyên nhân là bởi bộ vi xử lý cần thực hiện một chuỗi các thao tác như nạp lệnh từ bộ nhớ, giải mã lệnh trước khi lệnh thực sự được thực thi. Hơn nữa việc thực hiện một cách tuần tự một chuỗi các lệnh để hoàn thành một chức năng mong muốn cũng làm tốc độ xử lý của vi xử lý thấp hơn rất nhiều các mạch ASIC. Để nâng cao hiệu năng tính toán, đồng thời giảm công suất tiêu thụ, đã có nhiều cải tiến đối với kiến trúc của các bộ xử lý được đề xuất như Superscale, VLIW (Very Long Instruction Words), SIMD (Single Instruction Multiple Data), MIMD (Multiple Instruction Multiple Data), … Bên cạnh đó, công nghệ chế tạo các bộ xử lý cũng không ngừng được cải tiến để nâng cao tần số hoạt động, tiếp đến tăng số lõi xử lý (từ đơn lõi tới hai lõi, và hiện nay là đa lõi) được tích hợp trên cùng một chip vi xử lý. Tuy nhiên về cơ bản các giải pháp này vẫn dựa trên phương thức xử lý được vận hành bởi dòng lệnh, do đó về cơ bản không thể giải quyết được tận gốc vấn đề mà phương thức xử lý vận hành bởi dòng lệnh đang phải đối diện như được nêu ở trên.
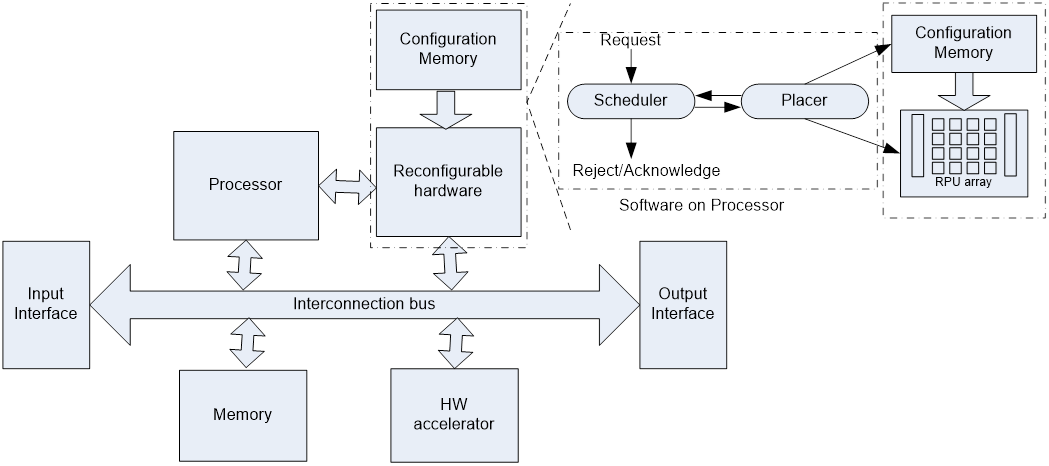
Hình 2: Kiến trúc của một hệ thống xử lý có thể tái cầu hình
Một giải pháp rất hứa hẹn cho việc giải quyết vấn đề nêu trên là các hệ thống tính toán có thể tái cấu hình (Reconfigurable Computing System [2] như chỉ ra trong Hình 2. Điểm khác biệt quan trọng của một hệ thống như vậy với các hệ thống xử lý thông thường là nó sử dụng các kết cấu phần cứng có thể tái cấu hình (Reconfigurable Hardware) cho việc tăng tốc độ thực thi các phần tiêu tốn nhiều thời gian tính toán trong thuật toán. Phần cứng có thể tái cấu hình thường được tổ chức thành một mảng các đơn vị xử lý có thể tái cấu hình RPU (Reconfigurable Processing Units). Các chức năng tính toán chuyên sâu của một thuật toán có thể được hoán chuyển vào hoặc ra khỏi mảng RPU hoặc ở thời gian chạy (tức sự cấu hình động) hoặc ở thời gian biên dịch (tức sự cấu hình tĩnh). Điều đặc biệt là sau khi mảng RPU được cấu hình cho một chức năng nào đó nó sẽ hoạt động giống như một đơn vị phần cứng chuyên dụng cho chức năng đó. Như chỉ ra trong Hình 1, hệ thống xử lý sử dụng các kết cấu phần cứng có thể tái cấu hình thường đạt được sự dung hòa giữa hiệu năng tính toán và tính mềm dẻo. Điều này là bởi vì phần cứng có thể tái cấu hình kết hợp được khả năng lập trình lại sau chế tạo (post-fabrication programmability) của bộ vi xử lý với phong cách tính toán song song hiệu năng cao của một vi mạch ASIC. Ở mức hệ thống, phần cứng có thể tái cấu hình thường được ghép với với một bộ vi xử lý nhúng. Bộ vi xử lý nhúng chịu trách nhiệm điều khiển hoạt động của các kết cấu có thể tái cấu hình và thực thi các phần mã không phù hợp để thực hiện trên phần cứng tái cấu hình.
Một trong những đặc tính đáng quan tâm của hệ thống tính toán có thể tái cấu hình là khả năng tái cấu hình động tại thời điểm hệ thống đang làm việc [3]. Ưu điểm lớn nhất của đặc tính này là nó cho phép tăng mật độ chức năng hiệu dụng của các ứng dụng được ánh xạ lên một đơn vị tài nguyên phần cứng. Nói cách khác, kỹ thuật này cho phép hệ thống xử lý có thể thực hiện cùng một số lượng ứng dụng với lượng tài nguyên phần cứng ít hơn khi dùng các mạch ASIC riêng biệt. Việc tăng mật độ chức năng của phần cứng đạt được bằng việc lập lịch các nhiệm vụ tính toán để chia sẻ theo thời
gian cùng một tài nguyên phần cứng giống như việc quản lý bộ nhớ ảo trong máy tính. Việc chuyển đổi cấu hình chức năng của phần cứng được điều khiển bởi các bộ điều khiển cấu hình với sự trợ giúp của các bộ nhớ cấu hình.
Trên thực tế, khái niệm hệ thống tính toán có thể tái cấu hình được giáo sư Gerald Estrin đề xuất từ những năm 60 thế kỷ trước [2]. Tuy nhiên do hạn chế của công nghệ bán dẫn, phải đến cuối những năm 90 của thế kỷ trước khái niệm này mới nhận được sự quan tâm nghiên cứu của giới khoa học. Kể từ đó, kỹ thuật tính toán có thể tái cấu hình không ngừng phát triển theo thời gian cùng với sự phát triển của công nghệ bán dẫn. Bắt theo xu hướng của thế giới, những năm gần đây một số trung tâm nghiên cứu, các trường đại học ở Việt Nam cũng đã có những hoạt động hướng về lĩnh vực này như: Phòng thí nghiệm mục tiêu Hệ thống tích hợp thông minh của Trường Đại học Công nghệ, Phòng thí nghiệm Thiết kế vi mạch thuộc Trường Đại học Bách khoa Hà Nội, Khoa Điện – Điện tử và CNTT của Trường Đại học Bách khoa Tp.HCM, Trung tâm Nghiên cứu và Đào tạo về Thiết kế vi mạch (ICDREC), thuộc ĐHQG TpHCM… Tuy nhiên phần lớn các cơ sở nghiên cứu ở Việt Nam hiện nay vẫn chủ yếu tập trung vào hướng ứng dụng các chip FPGA thương mại trong việc tạo ra khả năng tái cấu hình cho các hệ thống tính toán. Trong số các nhóm nghiên cứu trong nước, nghiên cứu đầu tiên về kiến trúc mảng có thể tái cấu hình lõi thô CGRA đã được nhen nhóm bởi Phòng thí nghiệm Hệ thống tích hợp thông minh (PTN SIS) của Trường Đại học Công nghệ trong một vài năm gần đây. Nhóm nghiên cứu thuộc PTN SIS bước đầu đã đạt được một số kết quả trong việc phát triển một mảng tính toán có thể tái cấu hình lõi thô và đã có một số công trình được công bố trong nước và quốc tế về lĩnh vực này như: [19][24][25][20][23][24][25]. Bước đầu, nhóm đã đưa ra được mô hình tính toán cho phần lõi xử lý của mảng CGRA. Mô hình tính toán này đã được mô hình hoá bằng cả ngôn ngữ C và VHDL và chứng minh được khả năng khai thác linh hoạt các cơ chế song song và tính cục bộ dữ liệu của các thuật toán để nâng cao hiệu năng xử lý. Hiện nay, nhóm nghiên cứu đang tập trung hoàn thiện thiết kế tổng thể của mảng CGRA, mô hình hoá kiến trúc ở mức RTL, tiến hành mô phỏng và hoàn thiện thiết kế theo hướng tối ưu năng lượng tiêu thụ, kiểm chứng thiết kế trên nền tảng FPGA và chuẩn bị cho công đoạn sản xuất IC (Integrated Circuit) thử nghiệm. Đây chính là mục tiêu hướng tới của việc đề xuất đề tài này.
Trên thế giới, nghiên cứu về kỹ thuật tính toán có thể tái cấu hình đã và đang trở thành một hướng nghiên cứu trọng điểm trong cả giới nghiên cứu hàn lâm và công nghiệp. Dựa theo mức lõi hay kích thước nhỏ nhất của một đơn vị logic có thể tái cấu hình (tính theo số bit nhị phân), các kết cấu phần cứng có thể tái cấu hình có thể được phân chia thành hai loại: kết cấu có mức lõi tinh (fine-grained granularity) và kết cấu có mức lõi thô (coarse-grained granularity) [2]. Phần lớn các chip FPGA (Field Programmable Gate Array) thương mại ngày nay đều thuộc lớp các kết cấu lõi tinh. Một vài hệ thống tính toán có thể tái cấu hình khác (ví dụ hệ thống Garp[6], Zynq 7000[7]) sử dụng FPGA như là kết cấu phần cứng cóthể tái cấu hình. Trong khi đó phần lớn các kiến trúc tái cấu hình lõi thô được nghiên cứu và đề xuất bởi các trường đại học hoặc các trung tâm nghiên cứu nhắm tới một miền ứng dụng xác định [5]. Trong giới nghiên cứu hàn lâm quốc tế, ở Mỹ có Đại học Stanford, Đại học California tại Berkeley, Đại học Carnegie Melton; ở Anh có Đại học Cambridge; ở Hà Lan có Đại học Delft; ở Đức có Đại học Kaiserslautern; ở Ý có Đại học Bologna; ở Trung Quốc có liên minh gồm Đại học Thanh Hoa, Đại học Nam Kinh, Đại học Giao thông Thượng Hải…đang có những dự án nghiên cứu chuyên sâu về hệ thống tính toán có thể tái cấu hình. Một số mảng kiến trúc có thể tái cấu hình lõi thô CGRA (Coarse-Grained Reconfigurable Architectures) nổi bật có thể kể đến gồm RaPiD[9], MorphoSys, PACT XPP-III[13], ADRES, REMUS-II[16][17], MORPHEUS[18].
Tóm lại, nhờ tiềm năng để tăng tốc độ tính toán cho một dải các ứng dụng trong khi vẫn đảm bảo được tính hiệu quả về công suất tiêu thụ, kỹ thuật tính toán có thể tái cấu hình đang là một hướng nghiên cứu thu hút được nhiều sự quan tâm nghiên cứu hiện nay. Kỹ thuật tính toán có thể tái cấu hình đã thể hiện ra một tiềm năng cực lớn cho việc ứng dụng vào một số lĩnh vực máy tính hiệu năng cao như phân tích cấu trúc, động lực học chất lỏng, mô hình phân tử, tin sinh học, vũ trụ học.v.v. đặc biệt trong các ứng dụng xử lý multimedia và truyền thông cho các thiết bị di động.
TÀI LIỆU THAM KHẢO
[1] M. Duranton et al., “The HiPEAC Vision,” HiPEAC Roadmap, 2014. [Online Available: www.hipeac.net/system/files/hipeacvision.pdf.
[2] Christophe Bobda, “Introduction to Reconfigurable Computing – Architectures, Algorithms, and Applications”. Springer, 2007.
[3] A. Shoa and S. Shirani, “Run-Time Reconfigurable Systems for Digital Signal Processing Applications: A Survey”, Journal of VLSI Signal Processing, Vol. 39, pp.213–235, 2005, Springer Science.
[4] G. Theodoridis, D. Soudris and S. Vassiliadis: “A Survey of Coarse-Grain Reconfigurable Architectures and Cad Tools Basic Definitions, Critical Design Issues and Existing Coarse-grain Reconfigurable Systems”, Springer 2008, p89-149.
[5] Diana Göhringer, Reconfigurable Multiprocessor Systems: Handling Hydras Heads – A Survey, ACM SIGARCH Computer Architecture News – HEART ’14, Volume 42 Issue 4, Setember 2014, Pages 39-44, ACM New York, NY, USA, DOI: 10.1145/2693714.2693722
[6] Callahan T. J., Hauser J. R., and Wawrzynek J.: “The Garp architecture and C compiler”, IEEE Comput. Vol.3, No. 4, 2000, pp.62–69.
[7] http://www.xilinx.com/products/silicon-devices/soc/zynq-7000.html
[8] Ebeling, C., Conquist, D., and Franklin, P.: “RaPiD: reconfigurable pipelined datapath”, Lect. Notes Comput. Sci. Misc., 1996, 1142.
[9] S. Goldstein et al., “PipeRench: A Reconfigurable Architecture and Compiler”, IEEE Computers, pp. 70–77, April 2000.
[10] S. Goldstein, H. Schmit, M.Moe, M.Budiu, S. Cadambi, R. Taylor, and R. LEfer, “PipeRench: A Coprocessor for Streaming Multimedia Acceleration”, in Proc. of International Symposium on Computer Architecture (ISCA), pp. 28–39, 1999.
[11] H. Singh, M. H. Lee, G. Lu, et al.: “MorphoSys: an integrated reconfigurable system for data-parallel and computation-intensive applications,” Computers, IEEE Transactions on, vol. 49, pp. 465-481, 2000.
[12] X. Technologies, “XPP-III Processor Overview”, White Paper, July 13
2006.
[13] M. K. A. Ganesan, et al., “H.264 Decoder at HD Resolution on a Coarse Grain Dynamically Reconfigurable Architecture”, International conference on Field Programmable Logic and Applications, pp. 467-471, 2007.
[14] B. Mei, S. Vernalde, D. Verkest, et al., “ADRES: An architecture with tightly coupled VLIW processor and coarse-grained reconfigurable matrix“, Proc. of Int. Conf. on Field Programmable Logic and Applications (FLP), pp. 61–70, 2003.
[15] B. Mei, M. Berekovic and J-Y. Mignolet.: “ADRES & DRESC: Architecture and Compiler for Coarse-Grain Reconfigurable Processors”, Fine- and Coarse-Grain Reconfigurable Computing, chapter 6, pp.255-297, 2007.
[16] M. Zhu, L. Liu, S. Yin, et al.: “A Cycle-Accurate Simulator for a Reconfigurable Multi-Media System,” IEICE Transactions on Information and Systems, vol. 93, pp. 3202-3210, 2010.
[17] Xinning LIU, Chen MEI, Peng CAO, Min ZHU, and Longxing SHI: “Date Flow Optimization of Dynamically Coarse Grain Reconfigurable Architecture for Multimedia Applications”, IEICE Trans. on Information and Systems,Vol. E95-D, No. 2, pp. 374-382.
[18] Nikolaos S. Voros, Michael Hübner, Jürgen Becker, et. al.: MORPHEUS: A heterogeneous dynamically reconfigurable platform for designing highly complex embedded systems, Journal ACM Transactions on Embedded Computing Systems (TECS) Volume 12 Issue 3, March 2013.
[19] Hung K. Nguyen, Peng Cao, Xuexiang Wang, Jun Yang, Longxing Shi, Min Zhu, Leibo Liu, Shaojun Wei: Hardware Software Co-design of H.264 Baseline Encoder on Coarse-Grained Dynamically Reconfigurable Computing System-on-Chip, IEICE TRANSACTIONS on Information and Systems (SCI index), Vol.E96-D, No.3, pp.601-615, 2013.
[20] KiemHung Nguyen, Peng Cao and Xuexiang Wang. An Efficient Implementation of H.264/AVC Integer Motion Estimation Algorithm on Coarse-grained Reconfigurable Computing System. Journal of Computers (JCP, ISSN 1796-203X), Special Issue on Parallel Computing (EI index), Vol 8, No. 3 (2013), 594-604, Mar. 2013, doi:10.4304/jcp.8.3.594-604.
[21] Xuexiang Wang, Hung K. Nguyen, Peng Cao, Zhi Qi, Hao Liu. Mapping method of coarse-grained dynamically reconfigurable computing system-on-chip of REMUS-II. In Proceedings of the 10th Workshop on Optimizations for DSP and Embedded Systems (ODES ’13), pp45-45, ACM New York, USA, Feb. 2013, ISBN: 978-1-4503-1905-8, DOI: 10.1145/2443608.2443619.
[22] KiemHung Nguyen, Peng Cao and Xuexiang Wang. Implementation of H.264/AVC Encoder on Coarse-grained Dynamically Reconfigurable Computing System. In Proceedings of the Fourth International Conference on Communications and Electronics (ICCE), 1-3 Aug. 2012, (EI index), pp483-488, DOI: 10.1109/CCE.2012.6315954.
[23] KiemHung Nguyen, Peng Cao and Xuexiang Wang. Mapping H.264/AVC Fractional Motion Estimation Algorithm onto Coarse-grained Reconfigurable Computing System, Advances in Intelligent and Soft Computing, 2012, Volume 159, Advances in Future Computer and Control Systems (EI index), Pages 299-309, DOI: 10.1007/978-3-642-29387-0_45.
[24] Hung K. Nguyen, Quang-Vinh Tran, Xuan-Tu Tran: Data Locality Exploitation for Coarse-grained Reconfigurable Architecture in Reconfigurable Networkon-Chips, The 2014 International Conference on Integrated Circuits, Design, and Verification (ICDV 2014), Hanoi 14-15/2014.
[25] Nguyễn Kiêm Hùng, Kiến trúc mảng phần cứng có thể tái cấu hình cho các ứng dụng xử lý đa phương tiện và truyền thông, đăng trong Kỷ yếu Hội nghị Quốc gia 2014 về Điện tử, Truyền thông và Công nghệ thông tin (REV-ECIT2014), Nha Trang 18-19/9/2014, p40-p47, ISBN: 978-604-67-0349-5.
[26] Hung K. Nguyen, Minh T. Phan: RTL Design of a Dynamically Reconfigurable Cell Array for Multimedia Processing, The National Foundation for Science and Technology Development (NAFOSTED) Conference on Information and Computer Science (NICS 2017), DOI 10.1109/NAFOSTED.2017.8108062.
[27] Hung K. Nguyen, Xuan-Tu Tran. An Efficient Implementation of Advanced Encryption Standard on the Coarse-grained Reconfigurable Architecture. VNU Journal of Computer Science and Communication Engineering (JCSCE), Vol. 32, No. 2, 2016, ISSN: 0866-8612, DOI: 10.1109/ATC.2016.7764800.
[28] Gaisler Research, “GRLIB IP Core User’s Manual”, Version 1.3.0-b4133, August 2013.
[29] Gajski D., Dutt N., Wu A., Lin, S.: “High-Level Synthesis, Introduction to Chip and System Design”, Kluwer Academic Pub. (1992).
[30] Kathryn S. McKinley, Steve Carr, Chau-Wen Tseng: “Improving Data Locality with Loop Transformations”, ACM Transactions
on Programming Languages and Systems (TOPLAS), Volume 18, Issue 4, July 1996,
Pages 424 – 453.
[31] S. Sohoni, and R. Min, et al. “A study of memory system performance of multimedia applications”. SIGMETRICS Performance 2001, pages 206–215.
[32] J. Jurely and H. Hakkarainen, “TI’s new ’C6x DSP screams at 1.600 MIPS. Microprocessor Report”, 1997.
[33] Garcia, A., Berekovic M., Aa T.V., “Mapping of the AES cryptographic
algorithm on a Coarse-Grain reconfigurable array processor”, International Conference on Application-Specific Systems, Architectures and Processors (ASAP 2008).
[34]Z. Alaoui Ismaili and A. Moussa, “Self-Partial and Dynamic Reconfiguration Implementation for AES using FPGA”, IJCSI International Journal of Computer Science Issues, Vol. 2, pp. 33-40, 2009.


{kind=link}